
El aprendizaje automático (Machine Learning, ML) se ha convertido en una herramienta clave en ciberseguridad. No solo ayuda a detectar ataques y anomalías en sistemas, sino que también permite automatizar la toma de decisiones frente a grandes volúmenes de datos.
En este artículo veremos un ejemplo sencillo pero poderoso: cómo usar un árbol de decisión para clasificar intentos de inicio de sesión como legítimos o sospechosos. Para ello, trabajaremos con un dataset pequeño en Python y visualizaremos los resultados en un modelo de Machine Learning.
Paso 1: Importar librerías
En primer lugar, cargamos las librerías necesarias:
- pandas: para manejar datos en forma de tablas (DataFrames).
- scikit-learn (DecisionTreeClassifier, tree): para entrenar el árbol de decisión.
- matplotlib: para graficar el modelo.
Explicación línea por línea:
import pandas as pd → Cargamos pandas, que nos permitirá trabajar con datos en formato tabla (DataFrames).
from sklearn.tree import DecisionTreeClassifier → Importamos el clasificador de árbol de decisión de scikit-learn, que será nuestro modelo de ML.
from sklearn import tree → Cargamos utilidades adicionales de árboles (como plot_tree para visualizar el modelo).
import matplotlib.pyplot as plt → Cargamos matplotlib, la librería más usada para gráficos en Python.
Este es el entorno mínimo para experimentar con Machine Learning.
Paso 2: Crear el dataset de entrenamiento
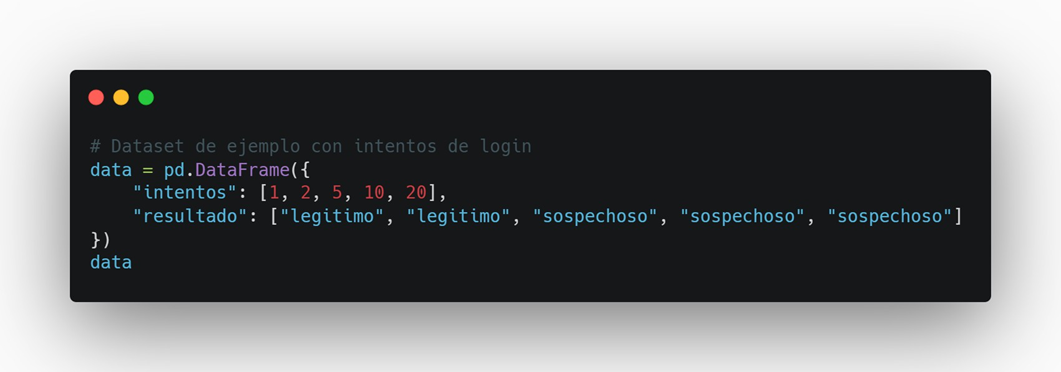
Definimos un dataset muy simple: el número de intentos de login y el resultado asociado.
Explicación:
- Usamos pd.DataFrame para crear una tabla con dos columnas:
- intentos: número de intentos de inicio de sesión.
- resultado: etiqueta que indica si el acceso fue legítimo o sospechoso.
- Con data mostramos la tabla dentro del notebook.
Resultados Esperados:
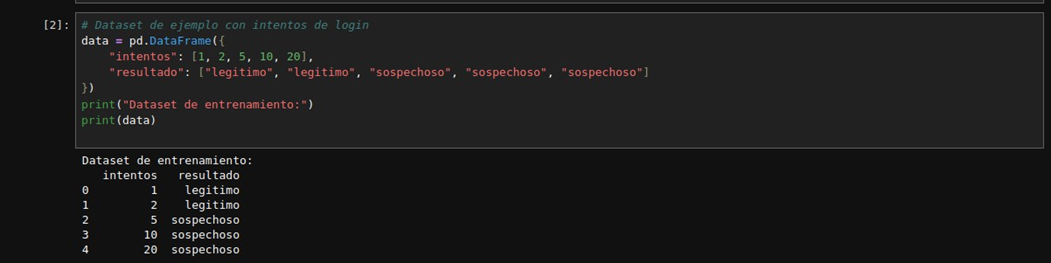
Aquí el modelo aprenderá que a mayor cantidad de intentos, más probable es que el acceso sea malicioso.
Paso 3: Entrenamiento y predicción
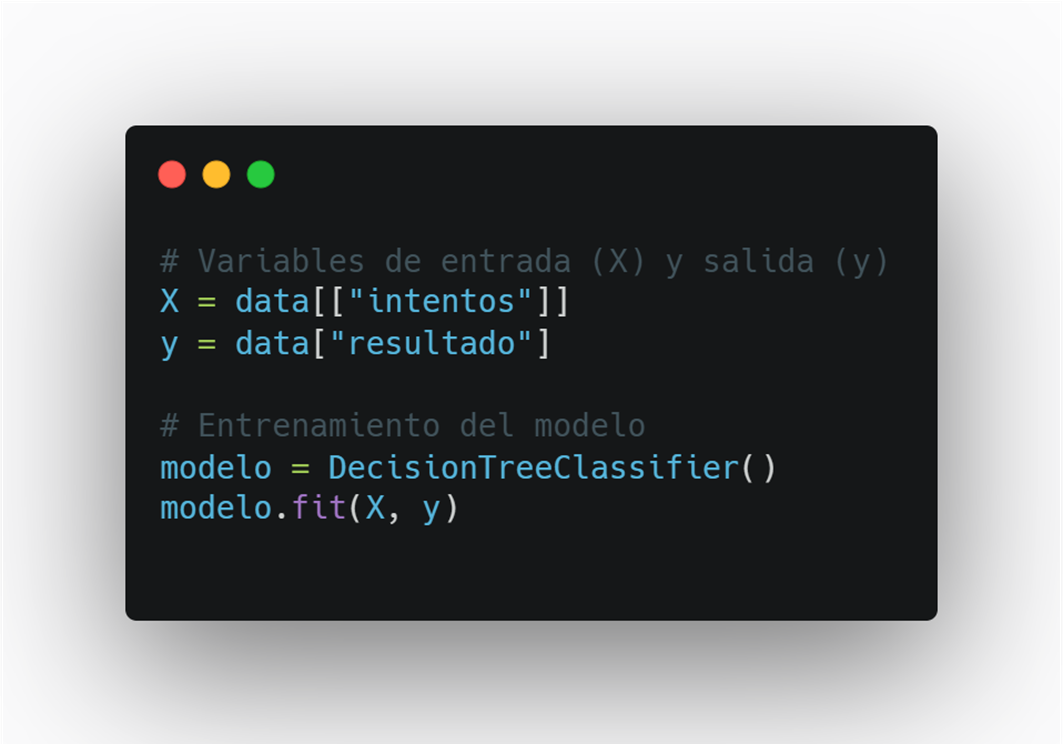
Una vez definido el dataset, separamos las variables y entrenamos el modelo.
Explicación:
Resultado Esperado:
X = data[["intentos"]] → Aquí seleccionamos la columna de entrada (feature) que usará el modelo.
y = data["resultado"] → Aquí seleccionamos la columna que queremos predecir (etiqueta).
modelo = DecisionTreeClassifier() → Creamos el objeto de nuestro árbol de decisión.
modelo.fit(X, y) → Entrenamos el modelo con los datos de entrada (X) y salida ( y ).
En la imagen vemos cómo Jupyter muestra la configuración interna del modelo de árbol de decisión ( DecisionTreeClassifier ) justo después de crearlo. Estos parámetros determinan cómo se construye y entrena el árbol.
Principales parámetros (con explicación sencilla)
Es la métrica que usa el árbol para decidir cómo dividir los nodos.
- Gini mide qué tan “puro” es un nodo (qué tan mezcladas están las clases).
- Alternativa: 'entropy' (usa información teórica).
Indica cómo elegir la mejor división en cada nodo.
- 'best' busca la división óptima.
- 'random' puede usarse para árboles más variados.
La profundidad máxima del árbol.
- None significa que no hay límite: el árbol sigue creciendo hasta separar todos los datos.
- Limitarlo (ej. max_depth=3 ) ayuda a evitar sobreajuste.
Número mínimo de ejemplos necesarios para dividir un nodo.
- Con 2 ya puede hacer una división.
Número mínimo de ejemplos en una hoja (nodo final).
- Con 1, cualquier ejemplo puede formar una hoja.
- Si lo subes, obligas al árbol a basar sus reglas en más datos → más robusto.
Número de características a usar en cada división.
- None significa que se usan todas las disponibles.
Controla la aleatoriedad.
- Si lo defines con un número (ej. 42 ), siempre obtendrás el mismo árbol → reproducible.
Sirve para darle más importancia a clases desbalanceadas.
- En un dataset con 95% logins legítimos y 5% sospechosos, balanced ayudaría a que no ignore a los sospechosos.
Parámetro de poda por complejidad.
- Si lo aumentas, el árbol se simplifica eliminando ramas poco útiles.
Ahora le pedimos al modelo que haga una predicción:
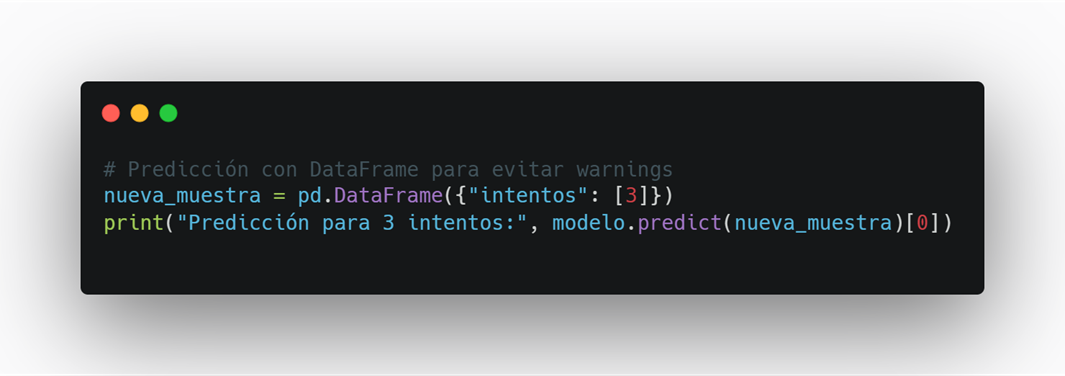
Explicación:
nueva_muestra = pd.DataFrame({"intentos": [3]}) → Creamos un nuevo dato de prueba con 3 intentos de login.
modelo.predict(nueva_muestra) → El modelo devuelve su predicción en base a lo que aprendió.[0] → Tomamos solo el primer resultado (en este caso, uno solo). Es decir, el modelo interpreta que hasta 3 intentos aún se pueden considerar normales.
Paso 4: Visualización del árbol de decisión
Explicación:
- plt.figure(figsize=(6,4)) → Define el tamaño de la figura.
- tree.plot_tree(...) → Dibuja el árbol de decisión:
- feature_names=["intentos"] → etiqueta para el eje de entrada.
- class_names=modelo.classes_ → nombres de las clases (“legitimo”, “sospechoso”).
- filled=True → colorea los nodos para que se entienda mejor.
- plt.show() → Muestra el gráfico.
- Nodo raíz divide en intentos ≤ 3.5 → “legítimo”.
- Nodo derecho: intentos > 3.5 → “sospechoso”.
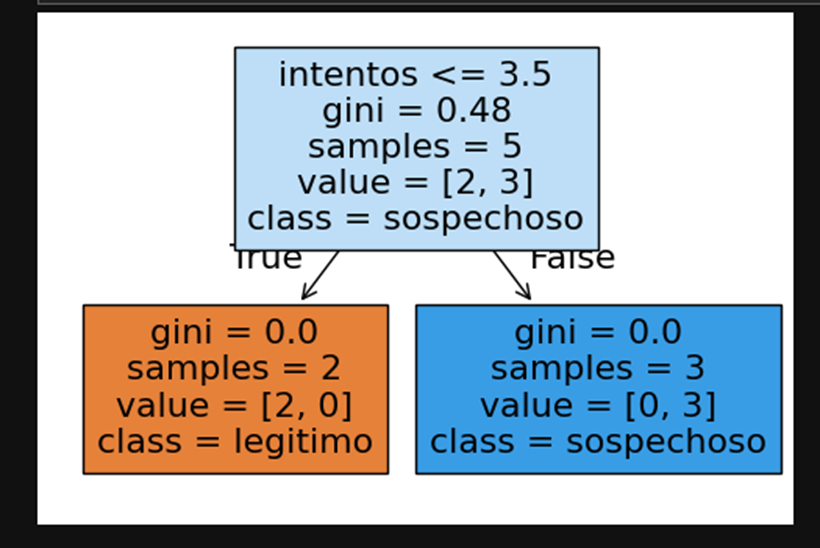
Esto se parece mucho a cómo piensan los sistemas de seguridad reales: establecen umbrales para detectar accesos sospechosos.
Reflexión en ciberseguridad
Este árbol tan simple ilustra un principio fundamental de la ciberseguridad: los umbrales de comportamiento. En nuestro caso, el modelo decidió que hasta 3 intentos de login se consideran normales y a partir del cuarto ya existe riesgo. Esto es exactamente lo que implementan sistemas reales para frenar ataques de fuerza bruta. Para un atacante, conocer o manipular estos umbrales puede ser la clave para evadir la detección (por ejemplo, distribuyendo intentos en intervalos largos). Para un defensor, en cambio, ajustar correctamente estos parámetros y combinar más variables como IP, geolocalización o tiempo entre intentos permite construir sistemas de detección más robustos y con menos falsos positivos.
Conclusión
- El ML puede traducirse en reglas fáciles de entender.
- Con pocos datos ya se pueden ilustrar patrones claros.
- El mismo enfoque puede escalar a datasets más complejos para proteger redes y sistemas reales.
Fuentes
Nuestro contenido más reciente
Conozca las novedades de nuestra empresa