
El aprendizaje supervisado entrena modelos con datos etiquetados para que aprendan patrones y luego predigan sobre ejemplos nuevos. En ciberseguridad, esto se usa para detectar phishing, URLs maliciosas, malware, intentos de login sospechosos, etc.
En este artículo verás, paso a paso, cómo construir un clasificador de URLs maliciosas con Regresión Logística y medir su rendimiento con Precision, Recall y F1-score. Además, generaremos imágenes nítidas (matriz de confusión, curva Precision–Recall, coeficientes) para ilustrar el resultado.
Conceptos básicos del aprendizaje supervisado
Conceptos clave:
- Feature (característica): un dato medible (ej.: longitud de URL, nº de subdominios, si contiene IP).
- Label (etiqueta): la “respuesta correcta” (ej.: maliciosa vs benigna).
- Entrenamiento: el modelo ajusta sus parámetros para reducir errores.
- Predicción: usar el modelo ya entrenado para decidir sobre nuevos casos.
- Evaluación: medir qué tan bien acierta (Accuracy), y sobre todo Precision, Recall y F1 cuando hay desbalance (pocas maliciosas).
- Precision: de todo lo marcado como malicioso, ¿cuánto sí lo era?
- Recall: de todo lo malicioso, ¿cuánto detecté?
- F1: equilibrio entre Precision y Recall (útil si te importan ambas).
- Generalización: que el modelo funcione con datos nuevos, no solo los de entrenamiento.
- Validación cruzada: probar el modelo en varias particiones para tener una estimación más estable.
- Regularización: “frena” la complejidad para evitar sobreajuste.
Ejemplo aplicado: clasificar URLs maliciosas (10 pasos)
Trabajaremos con un dataset simulado:
url_len (longitud)
num_subdom (subdominios)
has_ip (1/0)
tld_susp (1/0)
- Etiqueta malicious (1 = maliciosa, 0 = benigna)
Nota sobre las imágenes: todas las figuras de este artículo (matriz de confusión, curva Precision–Recall y coeficientes) se generan directamente desde el notebook. Esto garantiza que los gráficos reflejen exactamente los resultados del modelo y puedan reproducirse en cualquier entorno. En cada figura indico cómo leerla y qué significa para ciberseguridad.
Paso 1 — Portada del notebook (Markdown)
(Sin código de Python; es solo texto en tu primera celda del notebook).
Explica objetivo y salida esperada (Esto no es necesario pero es una buena practica).

Paso 2 — Imports (y %pip opcional)
Cargamos librerías y fijamos semilla para resultados reproducibles.
Qué hace:
numpy , pandas → datos.
matplotlib → gráficos.
sklearn.* → split, escalado, modelo, métricas y validación cruzada.
np.random.seed(42) → resultados estables.
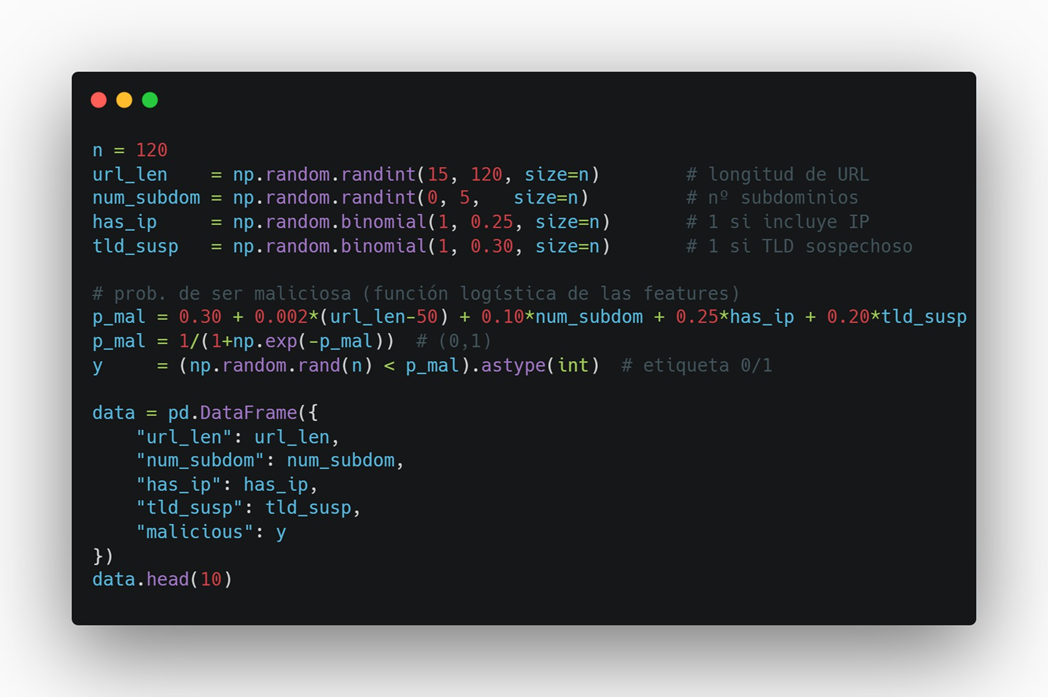
Paso 3 — Dataset simulado (features + label)
Creamos 120 ejemplos. La probabilidad de “maliciosa” aumenta con: longitud, subdominios, presencia de IP y TLD sospechoso.
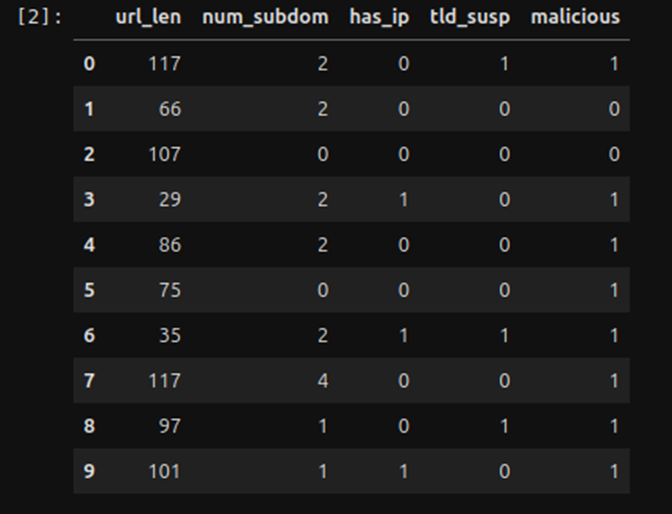
Qué verás: una tabla con 10 filas y 5 columnas.
Paso 4 — Train/Test + escalado
Hacemos split (75/25) estratificado (mantiene proporción de clases) y estandarizamos las features.
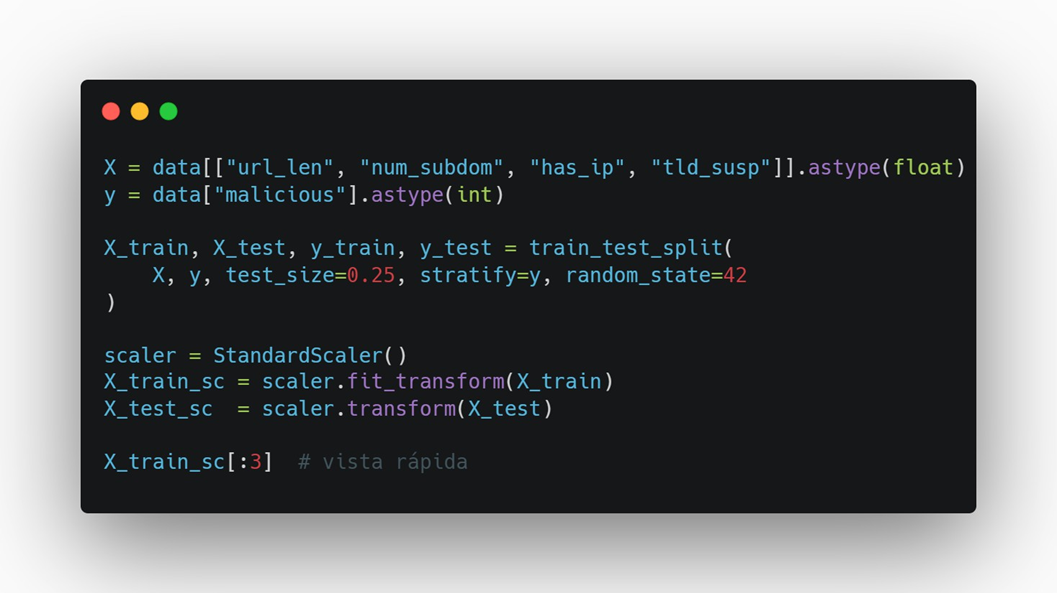
Por qué:
- Stratify evita particiones “cojas” (todo benigno o todo malicioso).
- Scaler mejora el comportamiento de modelos lineales (coeficientes comparables).
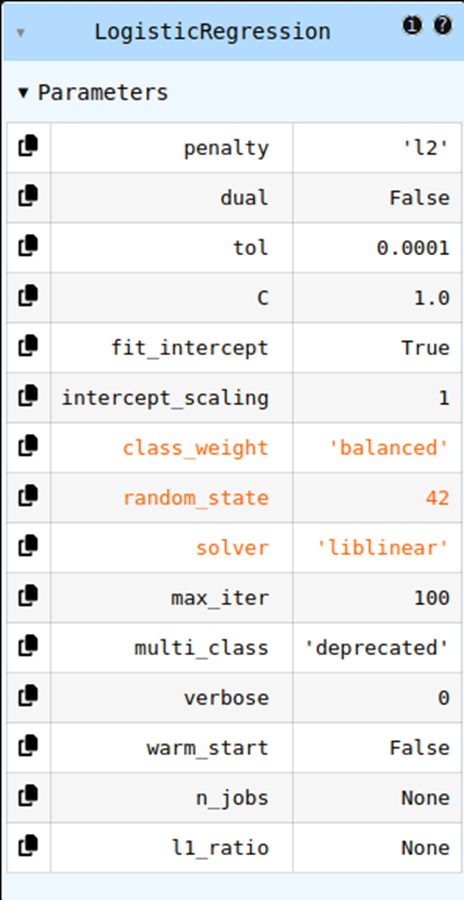
Paso 5 — Entrenar Regresión Logística
Usamos class_weight="balanced" para no ignorar la clase minoritaria.
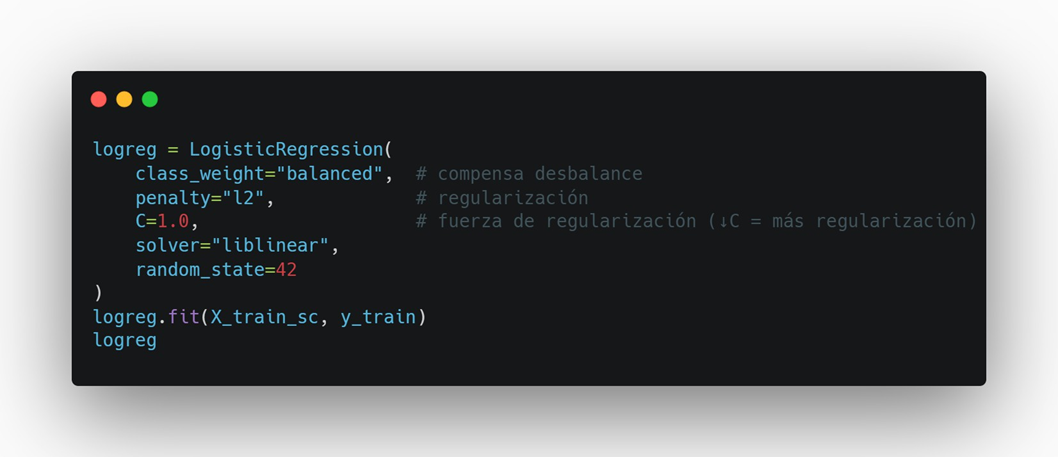
Lectura rápida:
- Penalización L2 estabiliza pesos.
- C controla “cuánto” regularizar.
- class_weight="balanced" sube el peso de la clase minoritaria (maliciosa).
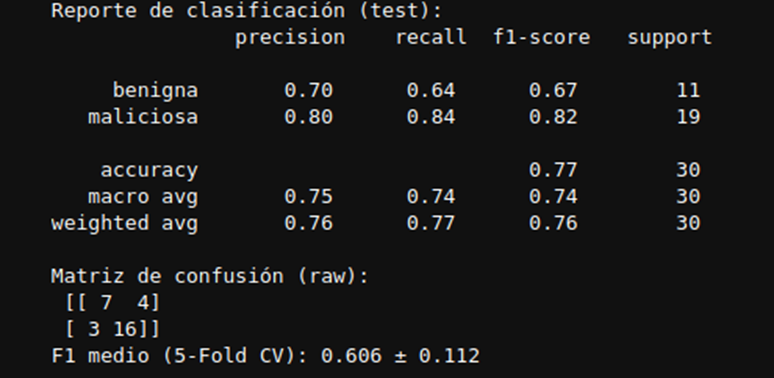
Paso 6 — Métricas (reporte + confusión) y F1 con CV
Medimos calidad en el set de prueba y además con 5-Fold CV para estabilidad.
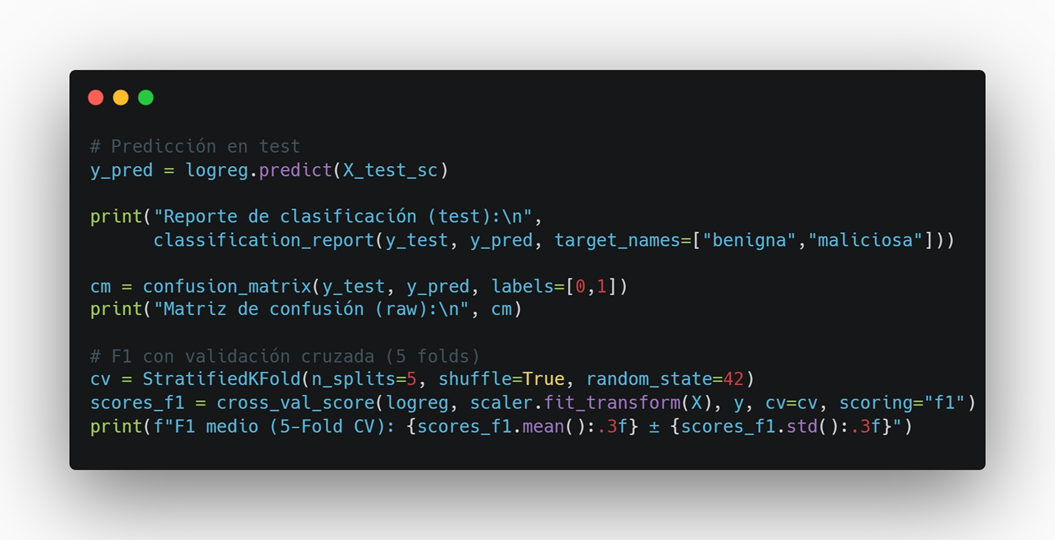
Cómo leerlo:
- El reporte muestra Precision/Recall/F1 por clase.
- La matriz muestra aciertos/errores (TP/TN/FP/FN).
- El F1 medio (CV) da una idea más robusta del rendimiento.
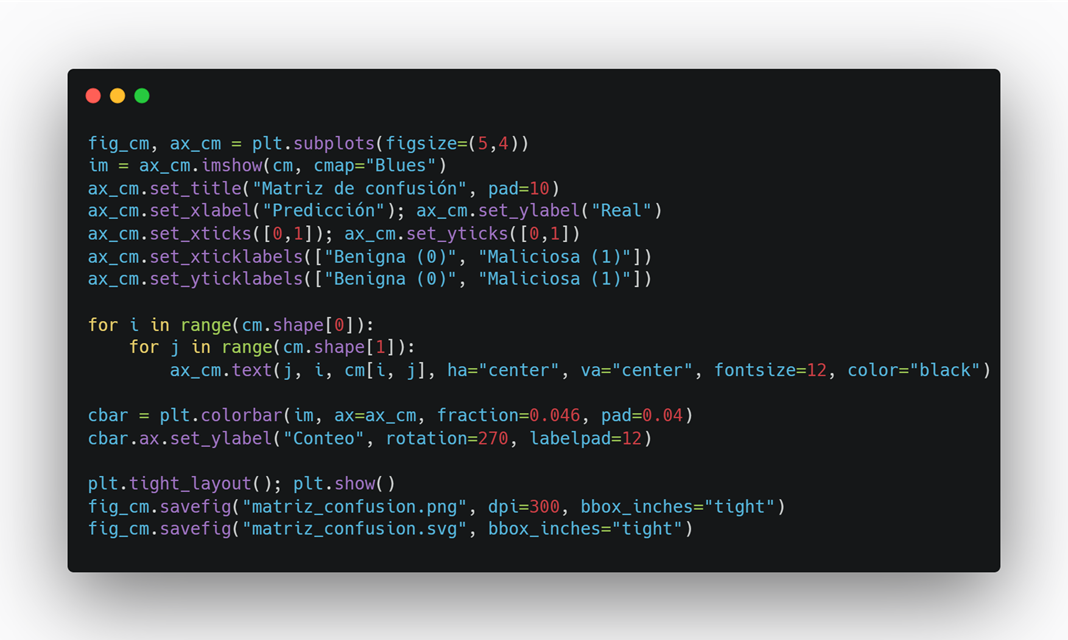
Paso 7 — Matriz de confusión (heatmap) + guardado
Gráfico coloreado y con conteos por celda (PNG/SVG en alta calidad).
Resultado Esperado:
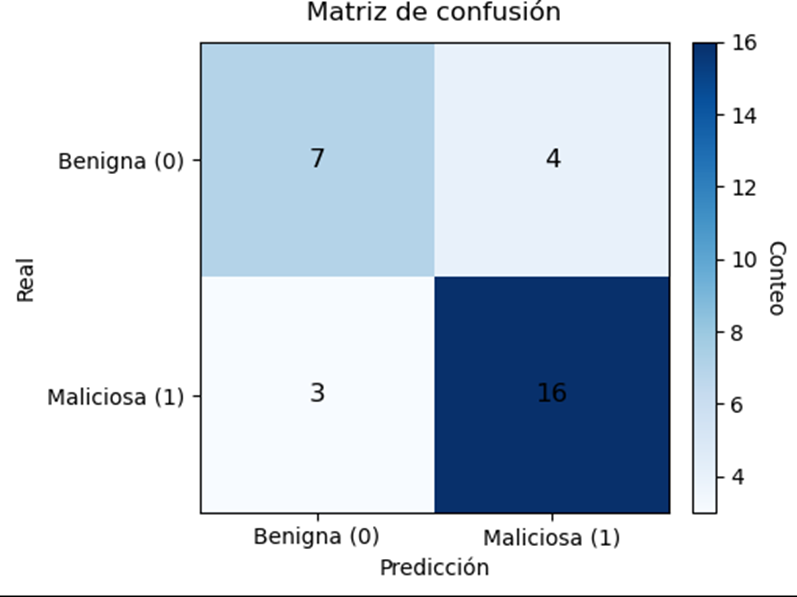
- TP (maliciosa→maliciosa) y TN (benigna→benigna) son aciertos.
- FP (falso positivo): molesta al usuario/analista.
- FN (falso negativo): crítico en seguridad (amenaza que se escapa).
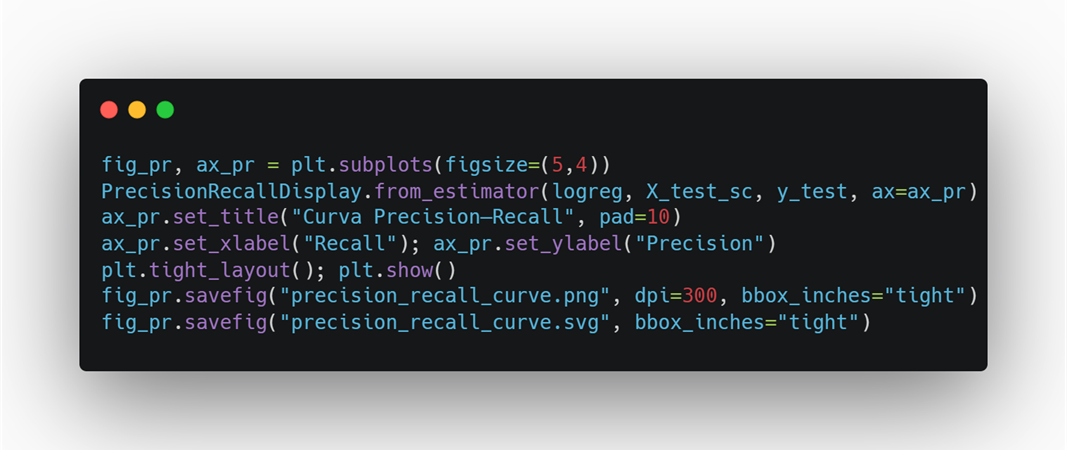
Paso 8 — Curva Precision–Recall + guardado
Excelente para clases desbalanceadas (mejor que ROC en muchos casos de seguridad)
Resultado Esperado:
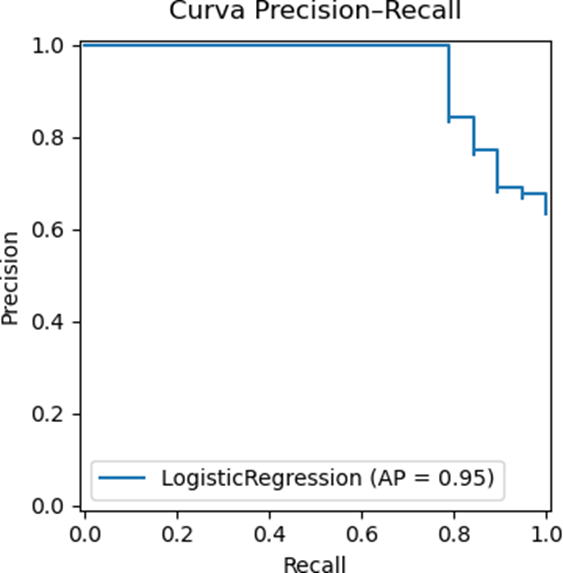
Lectura: cuanto más arriba se mantenga la curva a lo largo del recall, mejor equilibrio entre encontrar ataques y evitar falsos positivos.
Paso 9 — Importancia de características (coeficientes) + guardado
Gráfico interpretable: qué señales empujan la predicción a “maliciosa”.
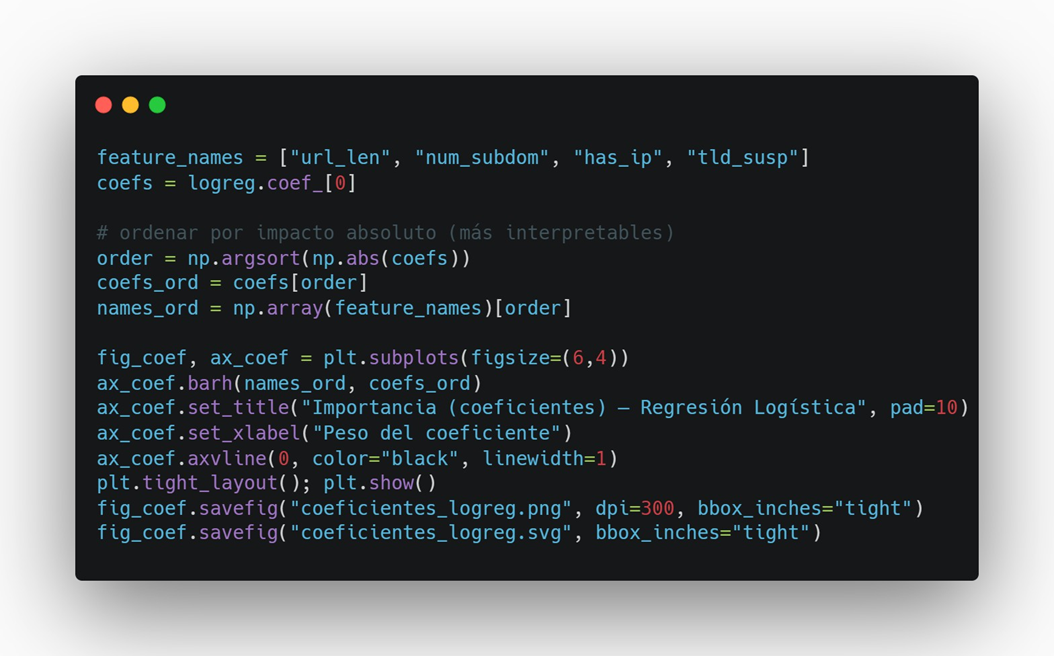
Resultado Esperado:
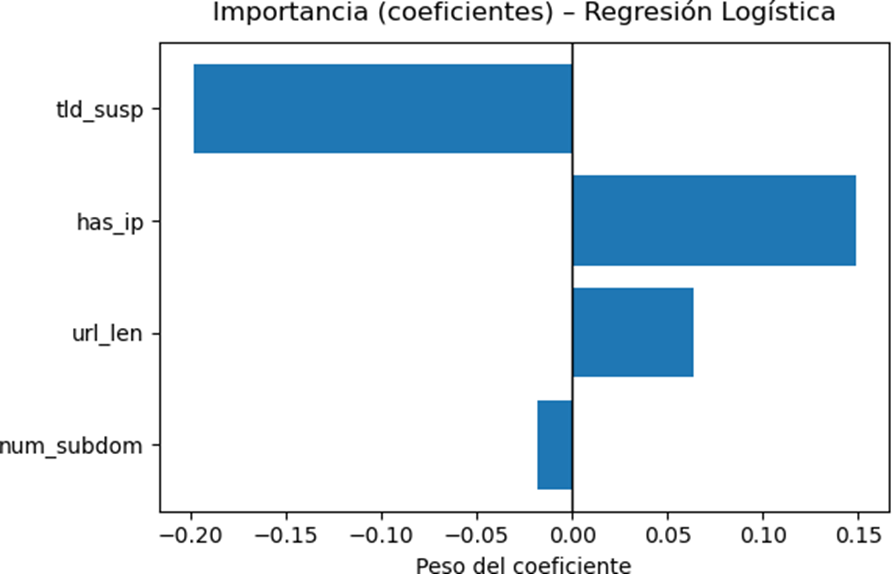
Lectura:
- Coeficiente positivo → aumenta prob. de maliciosa;
- Negativo → la reduce;
- |coef| grande → más influencia.
Paso 10 — Mini GridSearch (ajuste fino, opcional)
Probar distintas C y penalty para buscar mejor F1.
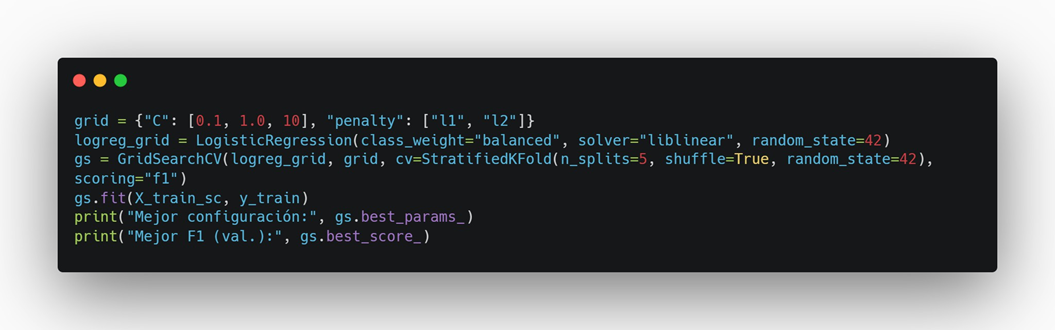
Resultado Esperado:

Interpreta:
- C pequeño → más regularización (modelo más simple).
- L1 puede “apagar” features (sparse), L2 suaviza.
Reflexión Red Team
El modelo aprende umbrales y combinaciones de señales: URLs largas, con IP y TLDs sospechosos tienen mayor probabilidad de ser maliciosas. Un atacante puede camuflar estas señales (acortar URL, evitar IPs, usar TLD legítimos). Un defensor, en cambio, puede:
- Reforzar features (edad del dominio, reputación ASN, WHOIS, tiempo entre peticiones).
- Revisar falsos negativos (lo más peligroso).
- Retocar umbrales/regularización para evitar sobreajuste y mejorar recall sin disparar falsos positivos.
Con un pipeline simple y explicable como Regresión Logística, más métricas adecuadas (Precision–Recall–F1), puedes construir detectores útiles para seguridad. Este ejemplo te deja armado: dataset, entrenamiento, evaluación, validación y gráficas en alta calidad listas para tu artículo. Desde aquí puedes comparar con SVM, Árboles/Random Forest o Gradient Boosting.
Fuentes
Documentación de scikit-learn (modelos, métricas y utilidades).
Nuestro contenido más reciente
Conozca las novedades de nuestra empresa